Regularización: la clave para evitar el sobreajuste
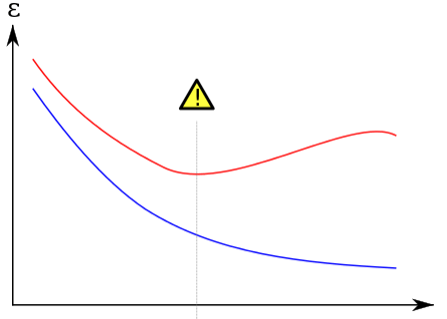
Cuando se trata de entrenar un modelo de aprendizaje automático, uno de los mayores desafíos es encontrar el equilibrio adecuado entre el ajuste del modelo y su capacidad para generalizar a nuevos datos. El ajuste excesivo, o sobreajuste, puede ocurrir cuando el modelo se ajusta demasiado a los datos de entrenamiento y pierde su capacidad para generalizar. Afortunadamente, existe una técnica llamada regularización que puede ayudar a controlar el sobreajuste y mejorar la capacidad del modelo para generalizar.
¿Qué es la regularización?
La regularización es una técnica de aprendizaje automático que se utiliza para reducir la complejidad de un modelo y evitar el sobreajuste. Consiste en agregar una penalización a la función de costo del modelo para desalentar los coeficientes de peso grandes y, por lo tanto, reducir la complejidad del modelo.
¿Cómo funciona la regularización?
La regularización funciona agregando un término de penalización a la función de costo del modelo. Hay dos tipos principales de regularización: L1 (Lasso) y L2 (Ridge). La regularización L1 agrega una penalización proporcional al valor absoluto de los coeficientes de peso, mientras que la regularización L2 agrega una penalización proporcional al cuadrado de los coeficientes de peso.
En general, la regularización L1 tiende a producir modelos más dispersos con menos características, mientras que la regularización L2 tiende a producir modelos más densos con más características.
Ejemplo práctico de regularización
Supongamos que estamos construyendo un modelo de regresión lineal para predecir los precios de las casas en función de diversas características, como el tamaño de la casa, el número de dormitorios y la ubicación. Si no utilizamos la regularización, es posible que nuestro modelo se ajuste demasiado a los datos de entrenamiento y pierda su capacidad para generalizar a nuevos datos.
Sin embargo, si utilizamos la regularización, podemos reducir la complejidad del modelo y evitar el sobreajuste. Por ejemplo, podemos utilizar la regularización L2 para agregar una penalización proporcional al cuadrado de los coeficientes de peso. Esto reducirá la magnitud de los coeficientes de peso y, por lo tanto, reducirá la complejidad del modelo.
Beneficios de la regularización
La regularización ofrece varios beneficios importantes para el entrenamiento de modelos de aprendizaje automático:
- Reduce el sobreajuste: La regularización ayuda a reducir el sobreajuste al reducir la complejidad del modelo.
- Mejora la capacidad de generalización: Al reducir el sobreajuste, la regularización mejora la capacidad del modelo para generalizar a nuevos datos.
- Mejora la estabilidad del modelo: La regularización ayuda a mejorar la estabilidad del modelo al reducir la sensibilidad a pequeñas variaciones en los datos de entrenamiento.
- Reduce el ruido en los datos: La regularización puede ayudar a reducir el ruido en los datos al eliminar características que no son relevantes para la predicción.
Conclusión
La regularización es una técnica importante en el aprendizaje automático que puede ayudar a reducir el sobreajuste y mejorar la capacidad de generalización del modelo. Al agregar una penalización a la función de costo del modelo, la regularización puede reducir la complejidad del modelo y mejorar su estabilidad y capacidad para generalizar a nuevos datos. Si está entrenando un modelo de aprendizaje automático, asegúrese de considerar la regularización como una herramienta importante para mejorar la calidad de sus predicciones.
Preguntas frecuentes
¿Cómo sé si mi modelo está sobreajustado?
Un modelo sobreajustado generalmente mostrará un rendimiento muy alto en los datos de entrenamiento, pero un rendimiento pobre en los datos de prueba o validación. Si nota una gran diferencia en el rendimiento del modelo entre los datos de entrenamiento y los datos de prueba, es posible que el modelo esté sobreajustado.
¿Cuál es la diferencia entre la regularización L1 y L2?
La regularización L1 agrega una penalización proporcional al valor absoluto de los coeficientes de peso, mientras que la regularización L2 agrega una penalización proporcional al cuadrado de los coeficientes de peso. En general, la regularización L1 tiende a producir modelos más dispersos con menos características, mientras que la regularización L2 tiende a producir modelos más densos con más características.
¿Cómo puedo seleccionar el parámetro de regularización adecuado?
La selección del parámetro de regularización adecuado puede ser un desafío. Una técnica común es utilizar la validación cruzada para probar diferentes valores del parámetro y seleccionar el valor que produce el mejor rendimiento en los datos de prueba.
¿La regularización siempre mejora el rendimiento del modelo?
No necesariamente. La regularización puede mejorar el rendimiento del modelo al reducir el sobreajuste y mejorar la capacidad de generalización, pero también puede reducir la precisión del modelo si se utiliza en exceso. La clave es encontrar el equilibrio adecuado entre el ajuste del modelo y su capacidad para generalizar.
Deja una respuesta