De la imagen al texto: Etapas del reconocimiento óptico de caracteres
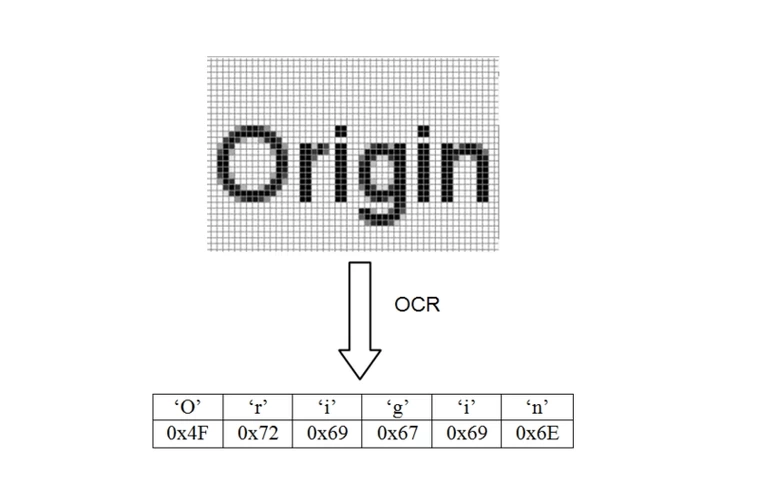
Cuando se trata de convertir información visual en texto digital, el reconocimiento óptico de caracteres (OCR, por sus siglas en inglés) es la tecnología clave en la que se apoya. OCR es un proceso que convierte imágenes escaneadas o de cámara en texto digital editable. Pero, ¿cómo funciona exactamente? En este artículo, exploramos las etapas del reconocimiento óptico de caracteres y cómo esta tecnología ha evolucionado con el tiempo.
Etapa 1: Preprocesamiento de imagen
La primera etapa del OCR es el preprocesamiento de imagen. En esta etapa, el software OCR escanea la imagen y la prepara para su procesamiento posterior. El preprocesamiento de imagen se realiza para mejorar la calidad de la imagen y para asegurarse de que sea legible para el proceso de OCR.
Una de las técnicas de preprocesamiento de imagen más comunes es el ajuste de contraste. Esto significa aumentar la diferencia entre los tonos claros y oscuros de la imagen para que los caracteres sean más visibles. También pueden ser necesarias otras técnicas, como la eliminación de ruido o la corrección de la perspectiva.
Etapa 2: Detección de caracteres
Una vez que se ha mejorado la calidad de la imagen, el software OCR busca los caracteres individuales en la imagen. Esto se hace utilizando algoritmos de detección de bordes y de segmentación de caracteres. Los algoritmos de detección de bordes buscan los bordes de los caracteres en la imagen, mientras que los algoritmos de segmentación de caracteres separan los caracteres individuales uno del otro.
En algunos casos, la detección de caracteres puede ser difícil debido a la calidad de la imagen o a la complejidad de los caracteres en sí mismos. Por ejemplo, los caracteres escritos a mano pueden ser mucho más difíciles de detectar que los caracteres impresos.
Etapa 3: Reconocimiento de caracteres
Una vez que se han detectado los caracteres individuales, el software OCR utiliza algoritmos de reconocimiento de patrones para reconocer los caracteres y convertirlos en texto digital. Estos algoritmos buscan patrones en los caracteres y los comparan con una base de datos de patrones conocidos.
El reconocimiento de caracteres puede ser un proceso difícil debido a la variabilidad inherente en la escritura. Por ejemplo, la letra "a" puede ser escrita de muchas maneras diferentes dependiendo del estilo de escritura de la persona que la escriba.
Etapa 4: Postprocesamiento de texto
Una vez que se ha realizado el reconocimiento de caracteres, el texto se somete a un proceso de postprocesamiento para corregir cualquier error que pueda haber ocurrido durante la detección o el reconocimiento de caracteres. Esto se hace utilizando algoritmos de corrección de errores que buscan errores comunes, como caracteres que faltan o que están mal identificados.
Conclusion
El reconocimiento óptico de caracteres es una tecnología importante para la conversión de información visual en texto digital. Aunque los algoritmos de OCR han mejorado significativamente con el tiempo, todavía existen desafíos en el reconocimiento de caracteres debido a la variabilidad inherente en la escritura y a la calidad de las imágenes escaneadas. Sin embargo, con el continuo avance de la tecnología, es probable que el OCR siga mejorando y se convierta en una herramienta cada vez más útil para la digitalización de información.
Preguntas frecuentes
¿Cómo se compara el OCR con la entrada de datos manuales?
El OCR es significativamente más rápido que la entrada de datos manuales y puede procesar grandes cantidades de información en un corto período de tiempo. Sin embargo, el OCR no es perfecto y puede haber errores de reconocimiento de caracteres, lo que puede requerir una revisión manual posterior.
¿Qué tipos de imágenes son más difíciles de procesar con OCR?
Las imágenes con baja resolución o baja calidad son más difíciles de procesar con OCR. También pueden ser difíciles las imágenes con caracteres escritos a mano o con caracteres que se superponen o están muy cerca uno del otro.
¿Puede el OCR procesar idiomas diferentes del inglés?
Sí, el OCR puede procesar una variedad de idiomas diferentes. Sin embargo, el rendimiento del OCR puede variar según el idioma y la calidad de la imagen.
¿Qué software OCR es mejor?
Hay muchos programas OCR disponibles en el mercado, cada uno con sus propias fortalezas y debilidades. Algunos de los programas OCR más populares incluyen ABBYY FineReader, Adobe Acrobat Pro, y OmniPage.
¿Cómo puedo mejorar la precisión del OCR?
Para mejorar la precisión del OCR, es importante utilizar imágenes de alta calidad y asegurarse de que los caracteres estén claramente separados y no se superpongan. También puede ser útil entrenar al software OCR en el reconocimiento de caracteres específicos, como los caracteres de su propia escritura.
Deja una respuesta