Evita errores de sobreajuste con la regularización
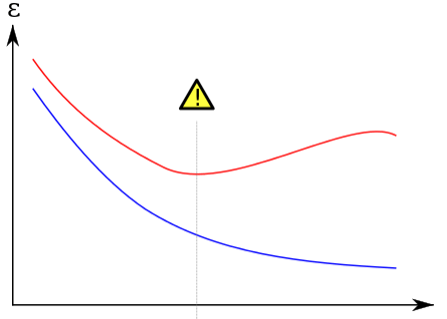
Cuando se trata de modelos de aprendizaje automático, una de las mayores preocupaciones es evitar errores de sobreajuste. El sobreajuste ocurre cuando un modelo se ajusta demasiado a los datos de entrenamiento, lo que resulta en una precisión alta en los datos de entrenamiento pero una precisión baja en los datos de prueba o nuevos. Esto puede ser un gran problema cuando se trata de aplicaciones del mundo real, ya que el modelo no será capaz de generalizar bien a nuevos datos. Afortunadamente, hay una técnica llamada regularización que puede ayudar a evitar errores de sobreajuste.
La regularización es una técnica que se utiliza para evitar que un modelo se ajuste demasiado a los datos de entrenamiento. Esto se hace al agregar una penalización en la función de coste del modelo. Hay dos tipos principales de regularización: L1 y L2. La regularización L1 se refiere a la penalización de la magnitud absoluta de los coeficientes del modelo, mientras que la regularización L2 se refiere a la penalización de la magnitud cuadrada de los coeficientes del modelo. Ambas técnicas funcionan reduciendo los coeficientes del modelo y, por lo tanto, reduciendo la complejidad del modelo.
La regularización tiene varios beneficios. En primer lugar, ayuda a evitar errores de sobreajuste al reducir la complejidad del modelo. Esto significa que el modelo será capaz de generalizar mejor a nuevos datos. En segundo lugar, la regularización también puede ayudar a mejorar la interpretación del modelo al reducir la complejidad. Con un modelo más simple, es más fácil entender cómo funciona y cómo se relacionan las variables de entrada con la salida. En tercer lugar, la regularización también puede ayudar a evitar problemas de multicolinealidad, que ocurren cuando las variables de entrada están altamente correlacionadas entre sí.
A continuación, se presentan algunos tipos de regularización que se pueden utilizar para evitar errores de sobreajuste:
- Regularización L1
- Regularización L2
- Regularización Elastic Net
- Regularización de Dropout
- Conclusión
-
Preguntas frecuentes
- 1. ¿La regularización siempre mejorará la precisión del modelo?
- 2. ¿Cuál es la diferencia entre la regularización L1 y L2?
- 3. ¿La regularización puede ayudar a evitar problemas de multicolinealidad?
- 4. ¿Cuál es la mejor técnica de regularización a utilizar?
- 5. ¿La regularización solo se aplica a modelos de aprendizaje automático?
Regularización L1
La regularización L1 se refiere a la penalización de la magnitud absoluta de los coeficientes del modelo. Esto significa que el modelo intentará reducir la magnitud de los coeficientes a cero. En otras palabras, la regularización L1 puede ayudar a seleccionar automáticamente las variables más importantes para el modelo.
Regularización L2
La regularización L2 se refiere a la penalización de la magnitud cuadrada de los coeficientes del modelo. Esto significa que el modelo intentará reducir la magnitud de los coeficientes a un valor cercano a cero. La regularización L2 es muy útil cuando hay muchas variables de entrada, ya que puede ayudar a seleccionar automáticamente las variables más importantes para el modelo.
Regularización Elastic Net
La regularización Elastic Net es una combinación de la regularización L1 y L2. Esto significa que utiliza ambas técnicas de penalización para reducir la complejidad del modelo. La regularización Elastic Net es muy útil cuando hay muchas variables de entrada y se desea seleccionar automáticamente las variables más importantes para el modelo.
Regularización de Dropout
La regularización de Dropout es una técnica que se utiliza en redes neuronales para evitar errores de sobreajuste. La técnica de Dropout implica aleatoriamente apagar una cierta cantidad de neuronas en la red durante el entrenamiento. Esto obliga a la red a aprender de manera más robusta, lo que puede ayudar a evitar errores de sobreajuste.
Conclusión
La regularización es una técnica muy útil para evitar errores de sobreajuste en modelos de aprendizaje automático. La regularización puede ayudar a reducir la complejidad del modelo y seleccionar automáticamente las variables más importantes para el modelo. Además, la regularización también puede ayudar a mejorar la interpretación del modelo y evitar problemas de multicolinealidad. Al utilizar técnicas de regularización como la regularización L1, L2, Elastic Net y Dropout, los modelos de aprendizaje automático pueden ser más precisos y generalizar mejor a nuevos datos.
Preguntas frecuentes
1. ¿La regularización siempre mejorará la precisión del modelo?
No necesariamente. Si el modelo no se está sobreajustando, la regularización puede reducir la precisión del modelo. Es importante encontrar el equilibrio adecuado entre la complejidad del modelo y la precisión del modelo.
2. ¿Cuál es la diferencia entre la regularización L1 y L2?
La regularización L1 se refiere a la penalización de la magnitud absoluta de los coeficientes del modelo, mientras que la regularización L2 se refiere a la penalización de la magnitud cuadrada de los coeficientes del modelo.
3. ¿La regularización puede ayudar a evitar problemas de multicolinealidad?
Sí. La regularización puede ayudar a evitar problemas de multicolinealidad al reducir la complejidad del modelo.
4. ¿Cuál es la mejor técnica de regularización a utilizar?
No hay una técnica de regularización que sea mejor que las demás. La técnica de regularización a utilizar depende del problema específico y de los datos que se estén utilizando.
5. ¿La regularización solo se aplica a modelos de aprendizaje automático?
No. La regularización también se puede aplicar a otros tipos de modelos, como modelos estadísticos y modelos de regresión.
Deja una respuesta